Software is an expression medium. Humans need to experiment, express and refine their thoughts before producing a final product. Some days you are high, hmmm... tired, and a genius idea turns out to be stupid. As anything else that requires a lot of creativity, tracks have to be followed, steps have to be rolled back, alternatives paths have to be explored. It is thus not surprising that with its ability to perfectly store, restore and compare information, computers will soon be used to implement, depending on the speaker, change tracking, revision control, version control or source control.
Three generations of revision control tools
Marc J. Rochkind while at Bell Labs wrote SCCS in 1972. It is credited to be the first version control system ever built. Over the years a slew of version control systems followed in its path, most notably for open source developers: CVS, Subversion and git. As the most widely used free control systems in their time, we will use these examples to define three periods in version systems.
file history
The first generation of control system, whose cvs is a representative, introduced the concepts and features that now define these tools. Source files are stored in a repository, sometimes called depot or by language abuse "the source control system". It is a specially crafted database whose purpose is to store an history of file edits.
Writing software often requires the cooperation of many people. Edit conflicts, broken builds, regressions and other issues intrinsically linked to the development of intellectual work are bound to arise. In the world of ideas, history is not a smooth linear path forward. Hence branches, tags and merges have inherently been built into source repositories early on.
Simply put each branch defines an alternate history. For example, when CEO Bill is scheduled to appear on investor's talk to announce the next version of *product* will ship May 1st, deep in developer's den, it gets decided that Bob will make sure that *product* will work flawlessly by then while Alice will focus on the next generation features. As changes often equates with risk, Bob wants to make the least amount of changes necessary to meet the deadline. On the other hand Alice sees the lock down as a risk for her research activities. She needs to be free to make wide ranging modifications, bounce ideas in, back them out. Both thus agree to fork the current repository in two branches, one for each of their specific purpose. Later, some of Bob's fixes might be useful to Alice so they would merge, sometimes referred as integrate, those from Bob's branch into Alice's. Alice's might also stumble upon some useful things for Bob and thus some integration might also go the other way after Bob agrees with the risk asessment.
It seems obvious that branch forks and merges are interesting point in the inter-winded repository histories. The time Bob packages the product for customer release looks also like a worthwhile event to remember; first because of the party Bill threw after six months of sweat and tears for everyone to get there; second because customers will report issues against the code in that package. This event is neither a fork nor a merge and does not appear as anything special on the timeline. Thus Bob tags, i.e. assigns a meaningful name to, the release point on his branch. Tags are thus decorations on the repository, a way to find of historical events of interest.
Meaning is where the first generation source control systems show their limits. Technologically revision systems like cvs is that they are file-centric. It is straightforward to retrieve a copy of the repository as of a specific tag but what happens when you are looking for event that has no associated tag? Each file has its own revision number. That makes even reverting your latest changes a challenge if you edited multiple files. The file-centric view of first generation source control systems also impacts merges. It is straightforward to integrate all of a branch content into another one but what about if you want to apply changes selectively? Those two problems, at the heart of many
The first generation of source control tools introduced the concepts of repository, branches, merges and tags. Their file-centric view while associated meaning to each change was becoming increasingly critical to software development as risk management drove them to the history books when the changesets generation appeared.
change sets
Today any decent source control tool has a notion of atomic changesets in a way or another. A changeset atomically identifies a set of edits (or patch) the entire repository. So while the previous generation of tools tracked the history on each file, the changeset generation reversely ties files to historical event.
The conceptual shift permits both to easily roll back to a specific point in the history as well as merging specific changes between branches. As we have seen before, these are two of major usage for source repositories so it is non negligible.
distributed repositories
The advances in affordable communication infrastructure and the willingness of a generation of developers to share their work freely put tremendous pressure on software development methodologies and tools.
Open source repositories are accessible online with any one on the Internet able to read from it. That is definitely today the most effective way to involve as many eyes as possible. Some pair of eyes also comes with a pair of hands. How do you get their work back into the repository?
For once since a project is available on the Internet, contributions come from anyone anywhere. In many cases people will have never seen each other. There are no vetting power like manager (no interview). Trust between the contributors need to be established somehow.
Next volunteers are random part-timers. They might have pulled a copy of the source tree for a personal need, found some bug, fix it and want to it back with the community because of morale obligations. Sporadic volunteers might have a vested interest in a project but are not interested by an active or leading role.
Until the introduction of distributed versioning systems, client-server architecture was king. A server administrator would painfully configure and manage permissions to the repository server. The architecture does not scale well when you work with hundreds of volunteers, most of them sporadic and untrusted.
The project's community at large relies on a stable repository and trusts maintainers to insure it remains mostly stable. Maintainers rely themselves on as many contributions as possible. The revision control tool as well as the development policies need to as painlessly as possible for a a volunteer-based project to thrive.
A distributed systems achieves this goal by cheaply setting-up and maintaining branches locally on a contributor's machine while sending patches between contributors. clone of repository. notion of branch merge model. no lock model. no maintenance of user accounts.
Three generations of revision control systems
| 1st generation | 2nd generation | 3rd generation | |
|---|---|---|---|
| representative | cvs | subversion | git |
| enabling feature | introduce concepts | atomic changesets | distributed branches |
| limit by design | file-centric | access rights | ? |
Policies
Revision control tools can ease or prevent a workflow model or another but ultimately it is the responsibility of a team to define its own integration policy.
Committers
As many workflows, it starts by defining access rights, who can read and who can write (or commit to) the revision control system. Reads will not modify the revision control system so read authorization can be managed through a third-party mechanism such as unix permissions, login accounts, etc. We thus will only concentrate on the number of committers.
unrestricted number of committers
In most cases, it is not advised for unknown and untrusted people to be able to commit changes to a source base. None-the-less a revision control tool can also be used to track comments on a blog post, wiki edits, and other use cases where unrestricted writes are a feature.
N committers
A restricted number of committers to the same repository is often the common model for source control. The trust built amongst the committers ensures that a project will not suffer from malain nor inadvertent sabotage. None-the-less as the number of committers grow, balancing between new features, source stability and release deadlines becomes an increasingly complex management issue.
1 committer
At first glance it might seem a special case of the N committers model but in fact it is a whole different class by itself. Since there is only one committer, all changesets have to be funneled through him/her in form of patches. Thus author and committer become two distinct roles in this model.
There are many advantages of a single committer model. Each changeset has been reviewed at least by one person, the committer. Not the least integration and release management is embodied to a single individual with full knowledge of what is going into a project and the power to include, delay, reject changesets as quality and deadlines require.
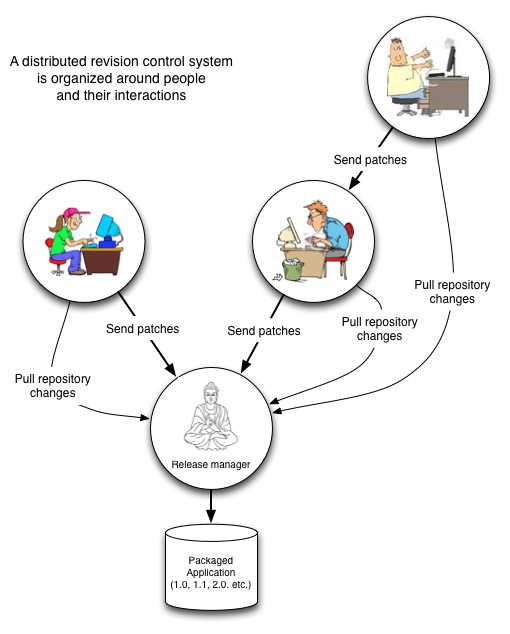
A single committer means a single point of failure, that is until the introduction of distributed revision control system such as git. By their very nature, those systems replicate the complete information necessary to manage a project on each local machine. It is thus possible to "elect" a machine/contributor to become the official release manager at any point. In open source development, the role will often flow to the person quickest and most reliable to balance between new features and code stability.
Changeset integration
Time, changesets and authors are the three major variables a revision control tool deals with. Most discussions about source control and branch management focus on time and changesets, disregarding authors and committers. Those discussions often generate more or less complex classic diagrams like the following.
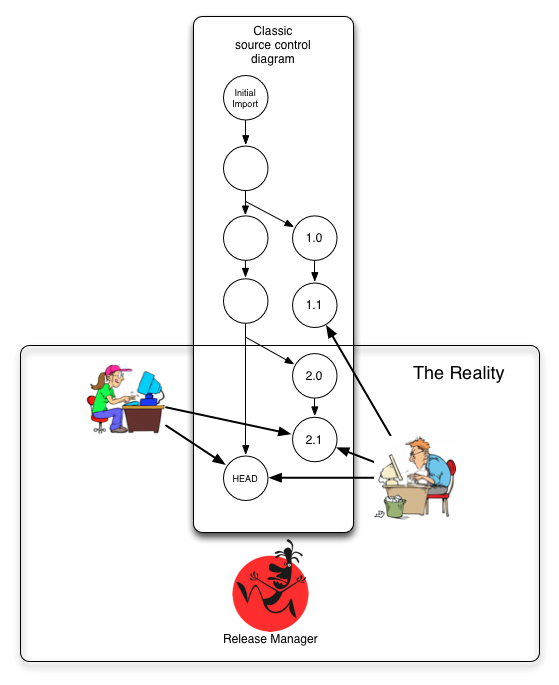
When you add authors back in the picture, things get murky. Soon you realize the importance of managing when and where committers are allowed to submit changesets. All branching strategy discussions are a way to help enforce those social policies without putting any human in the diagrams.
Distributed revision control tools were built to track patches on a contributor's local machine first and foremost instead of changesets on a remote server. Integration diagrams in terms of authors, committers and changesets better describe usage of tools such as git, relegating time to the background.